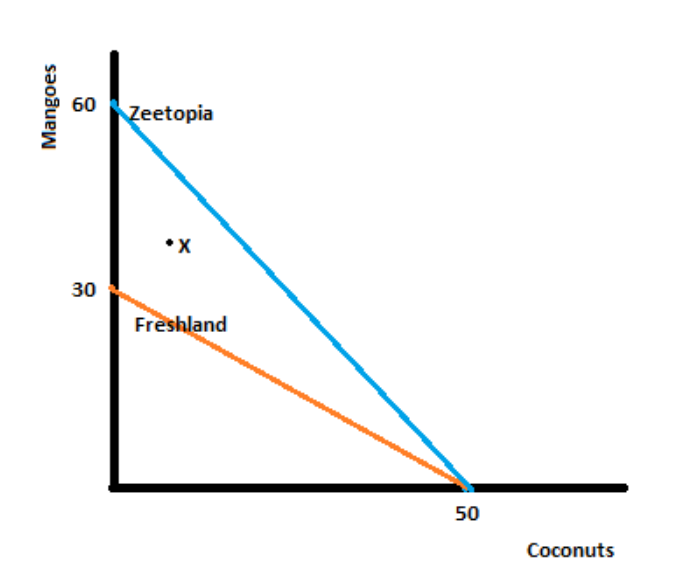
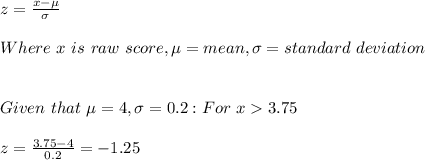Answer Part A:
1. There is a significant negative relationship between anxiety and academic performance, described as:
a. Subjects with lower anxiety scores have higher current GPAs, or;
b. Subjects who have lower current GPAs have higher anxiety scores.
Explanation:
We can tell that the two variables (anxiety and academic performance) have a negative relationship from its correlation coefficient (-.64). The negative sign shows the relationship, while the statistical significance (p < .01 or p < .05) shows whether there is a relationship or not.
Remember, the power of the correlation (as represented by the number 0.64) does not tell you whether a relationship actually happens or not. It can, however tell the strength of a relationship. A .64 is usually described as moderate to strong, depending on which reference you are using.
Also remember that this is not causation - we do not know which variable causes changes at the other. This is why it is possible to describe the relationship with either option (A) or (B). It is preferable to use a neutral sounding one such as the one stated above: By only saying that there is a negative relationship between the two variables.
2. There is no relationship between hours sleeping per night and academic performance.
Explanation:
A correlation coefficient of 0.00 means that there is no relationship between two variables. The closer a correlation coefficient to 0, the less likely do the variables have a relationship with one another.
Answer Part B:
1. It contributes to the interpretation of the findings by discussing whether:
(1) The measurement used is appropriate for the research conducted,
(2) There are any limitations from the current method of measurement.
Explanation:
The operational definitions in the study are not explicitly stated, but we can come to our own conclusions from the description of the study. They are:
Academic performance is the current GPA as reported by the research subjects.
Anxiety is the anxiety score summed from the research subjects' responses to the anxiety scale.
Interpretation is usually done during the discussion part of a research journal, after the statistical results have been reported. Discussing operational definitions would help determine whether the right measurement is used. Is the method free of biases? For example, Dr. Aguilera used a 5-point scale to measure the student's anxiety levels; there is a possibility of central tendency bias occurring.
2. Cohort effects may contribute to a possible bias over the result of the research. The variations in both anxiety levels and GPA may not be due to each other's influences, but perhaps instead caused by other age-related experience variables such as social media use.
Explanation:
Cohort effects are defined as a condition shared with same-aged groups of people which affected the result of the research. It is a form of bias, when it is not controlled. Dr. Aguilera's study is at risk of being affected with this since her research subjects are all university students.
In the study, we saw that Dr. Aguilera measured social media use, however, she did not seem to control this variable. It is possible that the variation in anxiety is moderated by social media, which then affects the subjects' GPA.
 2
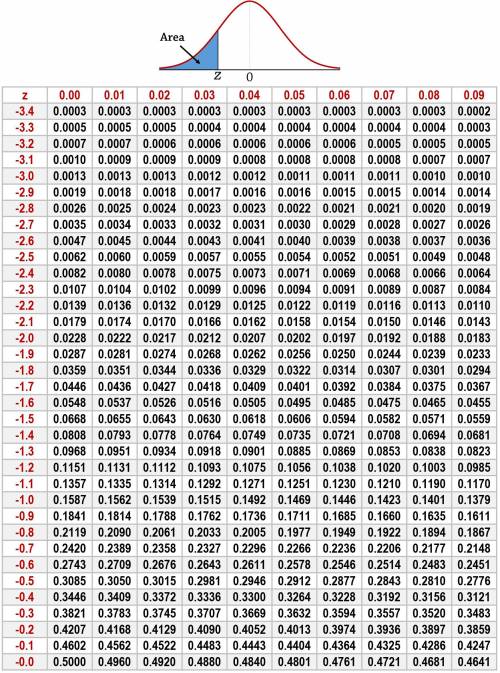
2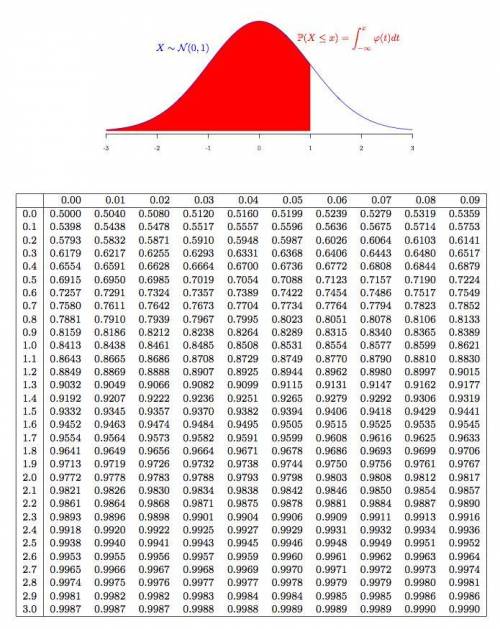
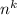 , including fixed time (
, including fixed time (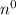 ), logarithmic time (log2{n}), linear (
), logarithmic time (log2{n}), linear (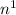 ), quadratic (
), quadratic (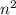 ), as well as another polynomial of higher degrees (such as
), as well as another polynomial of higher degrees (such as 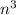 ). The runtime that grows more than
). The runtime that grows more than 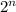 ), factorial time (n!), or anything else is super polynomial runtime.It seems it is perceived that polynomial runtime seems to be rational as well as super polynomial growth in order are rendered irrational. It is not necessarily ideal to have a polynomial run time, but it's least theoretically possible.
), factorial time (n!), or anything else is super polynomial runtime.It seems it is perceived that polynomial runtime seems to be rational as well as super polynomial growth in order are rendered irrational. It is not necessarily ideal to have a polynomial run time, but it's least theoretically possible.